简介
数据集概述
NYT数据集是关于远程监督关系抽取任务的广泛使用的数据集。该数据集是通过将freebase中的关系与纽约时报(NYT)语料库对齐而生成的。纽约时报New York Times数据集包含150篇来自纽约时报的商业文章。抓取了从2009年11月到2010年1月纽约时报网站上的所有文章。在句子拆分和标记化之后,使用斯坦福NER标记器(URL:http://nlp.stanford.edu/ner/index.shtml)来标识PER和ORG从每个句子中的命名实体。对于包含多个标记的命名实体,我们将它们连接成单个标记。然后,我们将同一句子中出现的每一对(PER,ORG)实体作为单个候选关系实例,PER实体被视为ARG-1,ORG实体被视为ARG-2。
示例: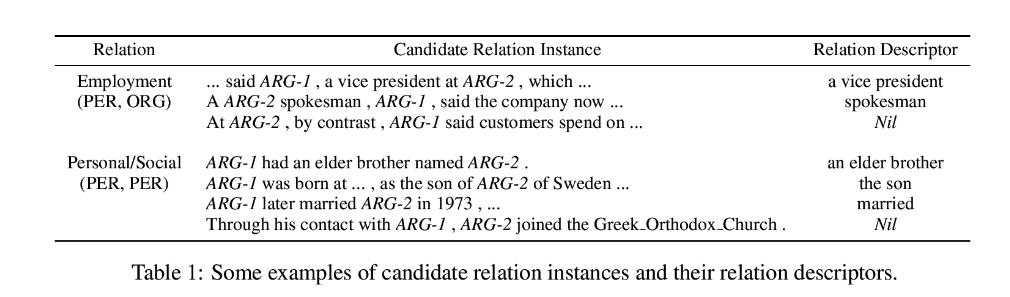
相关论文
1.GuoDong Zhou, Jian Su, Jie Zhang, and Min Zhang.2005. Exploring various knowledge in relation extraction. In Proceedings of the 43rd Annual Meeting of the Association for Computational Linguistics,pages 427–434, June.
2.Dmitry Zelenko, Chinatsu Aone, and Anthony Richardella. 2003. Kernel methods for relation extraction. Journal of Machine Learning Research,3:1083–1106
3.Fei Wu and Daniel S. Weld. 2010. Open information extraction using Wikipedia. In Proceedings of the tational Linguistics, pages 118–127, July.